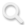转载自:阶跃星辰
比肩 Gemini、成本直降 90%!
向大家介绍我们最新端到端深度研究智能体模型:Step-DeepResearch。
它能做什么?
会思考:懂规划、会反思、还能自主验证信息的真伪,不只是数据爬虫。
更专业:结合高质量搜索 API,内置 2000 万+ 高质量文档库和 600+ 权威站点索引,过滤低信源信息干扰。
更聪明:独特的原子能力训练法,让模型把“专家思维”内化在骨子里。
在针对真实复杂场景的 ADR-Bench 评测中,Step-DeepResearch 表现出极强竞争力,在多个维度上全面超越海内外一线 DeepResearch 产品和模型,包括基于千亿级甚至万亿级参数 MoE 架构的 Gemini DeepResearch、OpenAI DeepResearch 等模型。
而 Step-DeepResearch 仅基于单智能体架构实现。
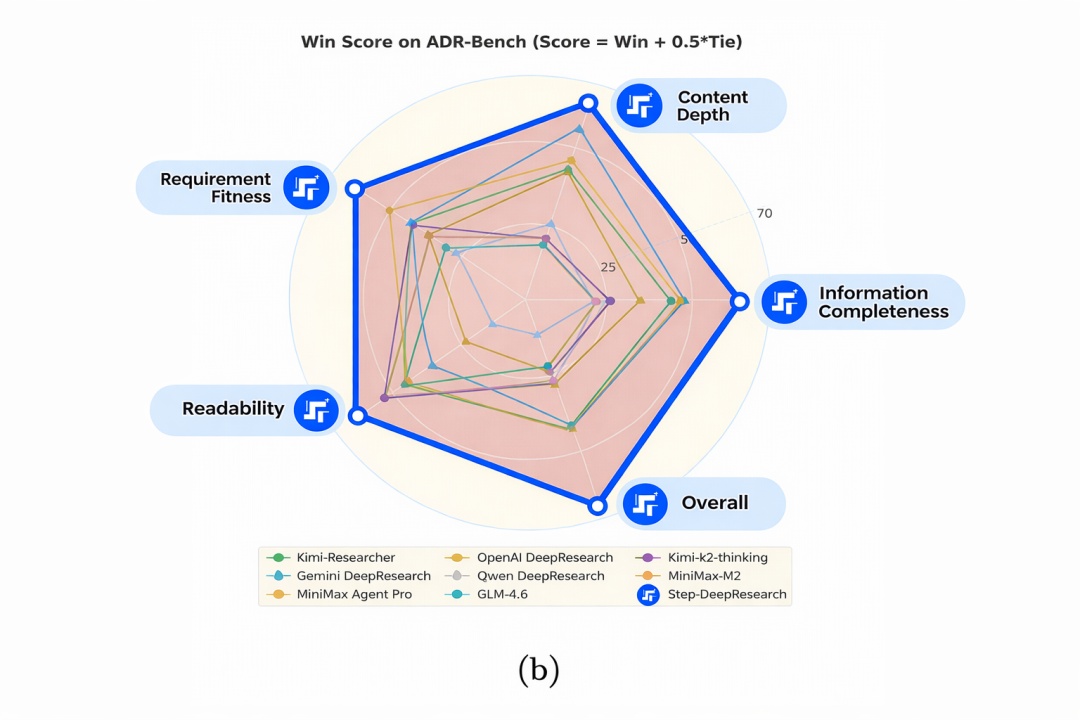
在我们的技术报告全面公开后,立刻引发海内外社区热烈讨论,并入选 HuggingFace Daily Papers。
现在,我们开启 API 内测,欢迎大家踊跃体验!
论文地址:https://arxiv.org/pdf/2512.20491
GitHub:https://github.com/stepfun-ai/StepDeepResearch
API 内测:https://wvixbzgc0u7.feishu.cn/share/base/form/shrcn8CP78PJgkjvvIh2C3EF3cc
官方主页:https://www.stepfun.com/deep-research-invitation
Step-DeepResearch 在多项权威基准测试中都达到全球顶尖水平。
在 Research Rubrics 上,Step-DeepResearch 得分 61.42%,仅次于 Gemini DeepResearch(约 63.69分),且超越了 OpenAI DeepResearch。
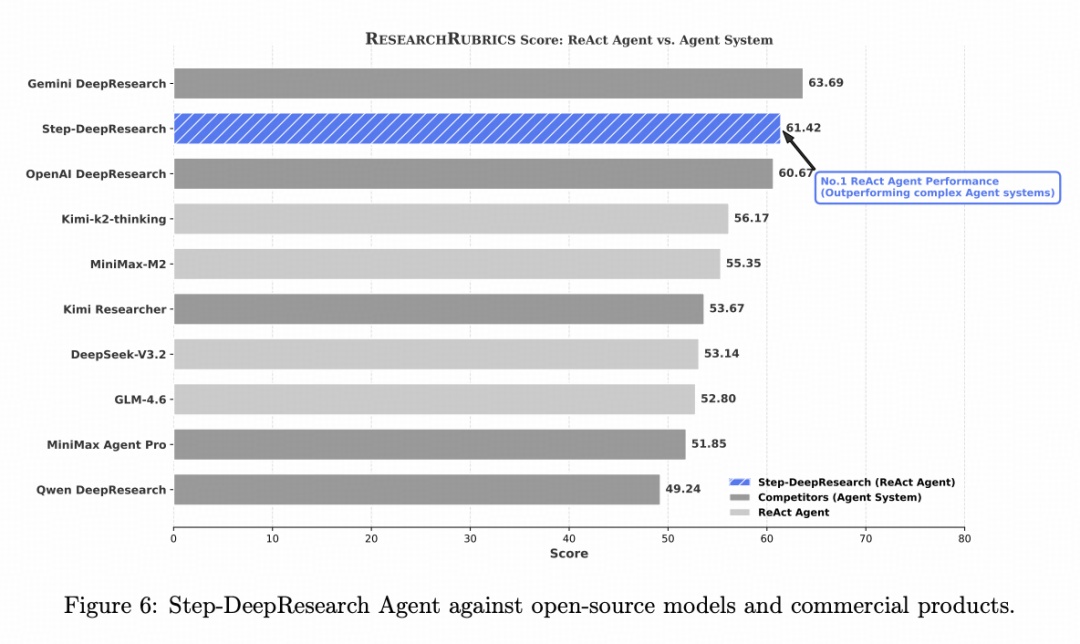
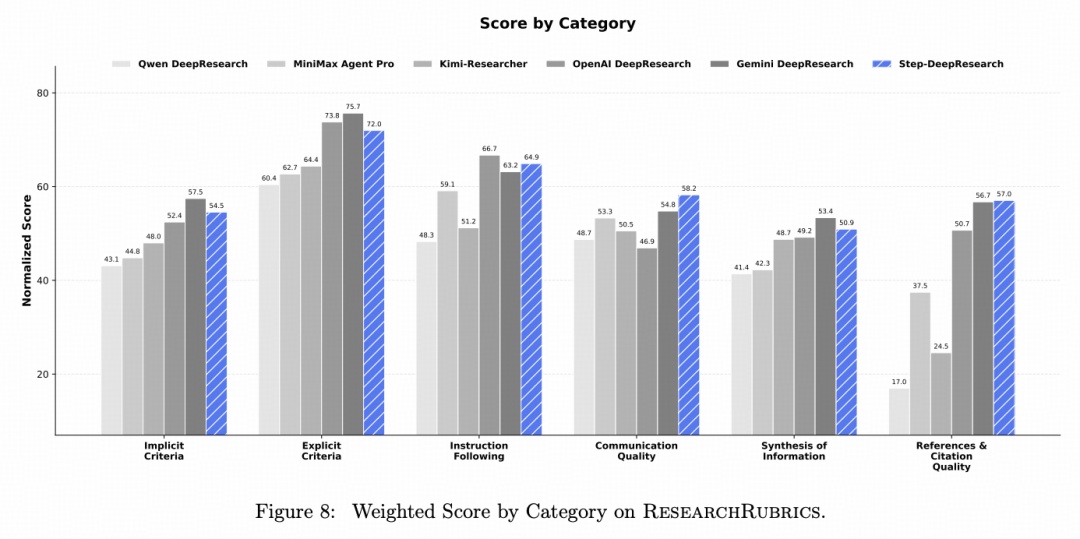
在“引用质量”和“沟通质量”两个维度上达到了行业最高水平。
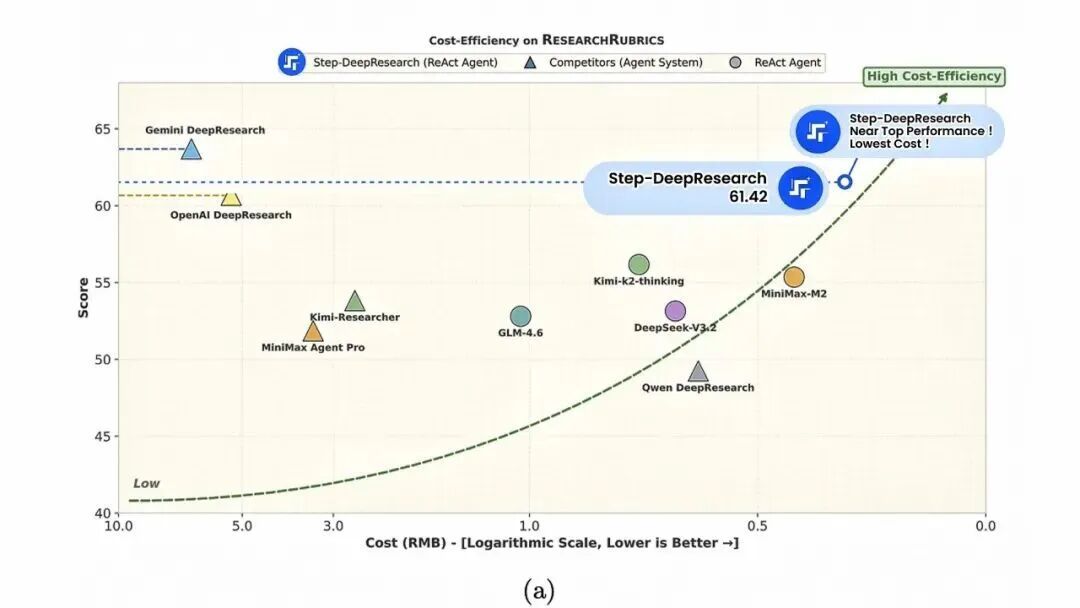
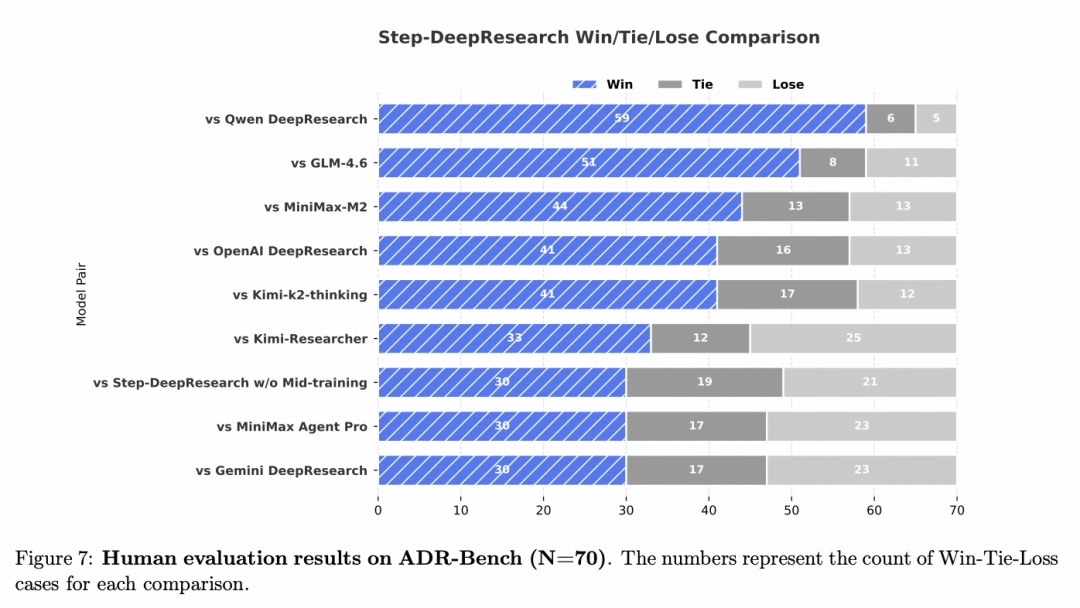
在针对真实研究场景的 ADR-Bench 评测中,Step-DeepResearch 的人类 Elo 评分在多个维度处于第一梯队。
特别是在与 Gemini DeepResearch等顶尖模型的直接博弈中,其“胜+平”率高达 67.1%,证明了其生成的报告质量已达到当前最先进水平。
▲上下滑动查看详细内容
Step-DeepResearch 的主要创新可归纳为3方面:
基于原子能力的数据合成策略
渐进式智能体训练范式
自建 ADR-Bench 评估体系
我们将深度研究能力拆分为四个原子能力,并针对性地合成数据进行强化。
规划与任务拆解:能将模糊、宏大的用户需求拆解为可执行的子任务,并根据环境反馈动态调整路径。
深度信息搜索:具备多跳推理能力,能在信息不完整时进行“主动拓扑行走”,挖掘隐藏实体。
反思与验证:拥有“自纠错”和“事实核查”能力,能识别自身错误并区分网络信息的真伪,通过跨源验证确保逻辑严密。
报告生成:通过中期训练(Mid-training)学习专家写作风格,并利用 SFT 确保报告严格遵循规划结构和引用规范。
我们的智能体训练范式主要包含三个阶段:
Agentic Mid-training:在预训练和微调之间加入 Mid-training,通过 32K 和 128K 两个阶段的上下文调度,注入原子能力,使模型内化“下一步行动”的决策逻辑,而非简单的“预测下一个 Token”。
SFT:侧重于长程决策轨迹的合成与领域适配,强化意图理解、规划执行及严格引用格式的遵循,解决模型在长时间研究任务中容易“分心”或“迷路”的问题。
RL:引入 Checklist-style Judger 奖励设计,将复杂的报告质量评估转化为细粒度的信号,进一步优化长程决策的鲁棒性。
在系统架构上,我们采用单智能体 ReAct 架构,避免复杂多智能体系统协作带来的系统冗余。
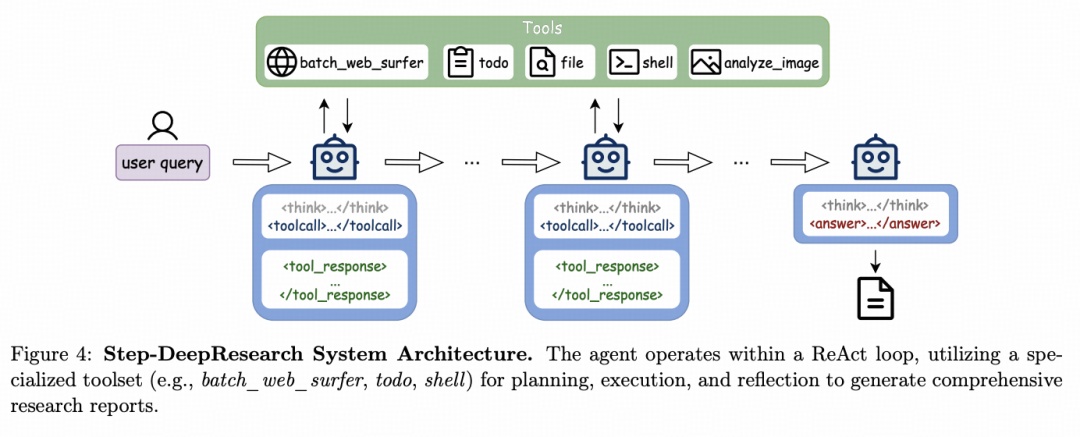
此外,为了填补中文深度研究评估的空白,我们还构建了 ADR-Bench,涵盖商业调研、政策分析、软件工程等 9 大领域,包含通用和专业(法律、金融)两个维度。该基准测试不仅关注搜索结果是否正确,更加关注研究过程中的逻辑严密性、意图识别深度以及长程决策的鲁棒性。
欢迎转发,但请注明出处“上海经信委”
觉得不错请点赞!