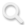我局官微“上海统计”已开设专栏“理论应用”,内容聚焦前沿理论、立足全球视野,以传播现代统计方法、实践和成功案例为主,助推统计人科研水平提高和统计事业的改革发展,欢迎大家及时关注分享。
本期推送“中国金融–房地产网络中的系统性风险:分数阶方程的建模与预测”。近年来,受房地产部门结构性调整影响,我国金融系统面临巨大压力。文章结合分数阶偏微分方程(Fractional-order PDEs, FoPDEs)与网络分析方法,提出了一个用于捕捉并建立系统性金融风险传染模型的混合框架。实证结果表明,对于日频数据,模型的平均相对准确率(MRA)达到 95.5%,在相同条件下优于LSTM与XGBoost。对于周频数据,模型的MRA为91.7%,高于XGBoost的90.25%。对参数动态与事件的进一步分析显示,当 ∆CoVaR 突然上升时,控制模型记忆效应的分数阶参数α往往处于较低水平。这表明在金融冲击期间,模型会对历史数据赋予更高权重,从而更有效地刻画风险动态的持久性。
近年,中国房地产市场进入深度调整期,叠加与金融体系复杂关系交织,金融–房地产风险传染研究与防控成为维护金融稳定与实现经济软着陆的关键环节。论文正是尝试使用具备记忆性与非局部性的数学工具——分数阶偏微分方程(Fractional PDEs, FoPDEs),来刻画和预测风险在金融–地产网络中的演化。
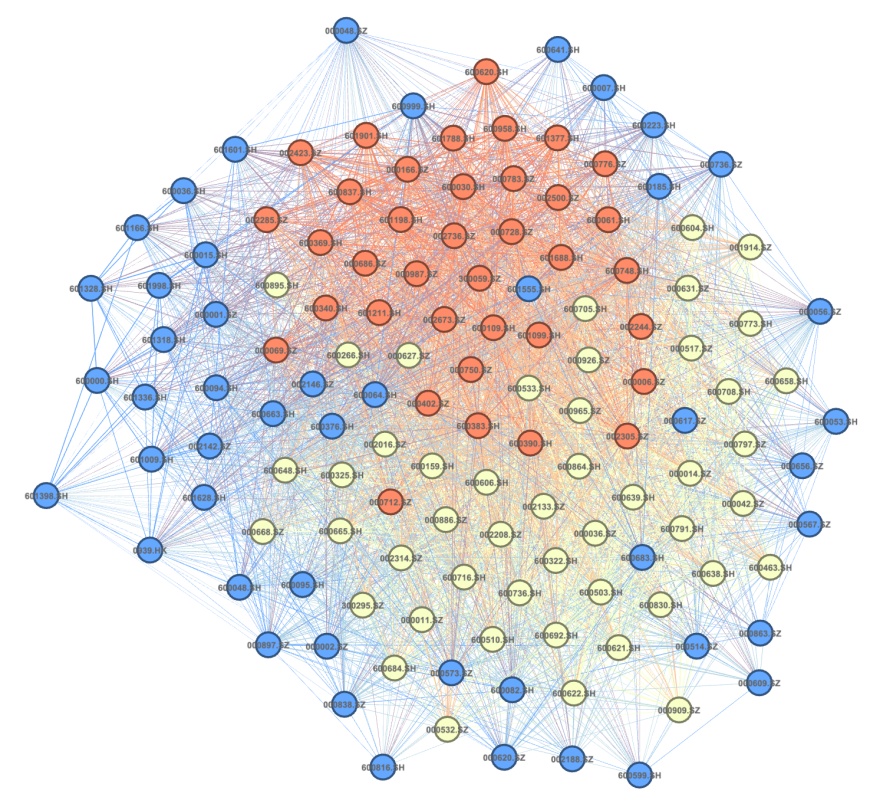
图1 金融网络示意图
一、研究问题与挑战
金融–房地产系统是一个高度互联的复杂网络。银行、券商、房地产开发商等机构之间存在着显性的资金往来,也存在隐性的市场依赖。一旦某类机构出现问题,风险就可能通过各种渠道扩散开来。这类风险的演化往往具有两个特征:一是非线性,小的扰动可能引发大的连锁反应;二是记忆效应,历史冲击会长时间影响未来的走势。
传统的统计方法(如GARCH类模型)虽能描述波动,但难以捕捉这种“长记忆”的现象。而机器学习模型(LSTM、XGBoost等)在预测上表现不俗,却常常缺乏可解释性。如何兼顾预测精度与机制解释,成为研究的难点。
二、方法创新:分数阶PDE+网络分析
作者提出的框架结合了三种方法:
01
网络建模
利用格兰杰因果检验和动态相关系数(DCC)构建金融–房地产的有向加权网络,并通过“Motif-8”模式识别和聚类,将机构划分为簇;
02
风险度量
采用∆CoVaR指标衡量某机构对系统整体的边际风险贡献;
03
分数阶PDE
在时间维度上引入分数阶导数 α,以捕捉风险的记忆效应;在空间维度上引入扩散项,模拟风险在不同簇之间的传播。
分数阶参数α的意义尤为关键:当α较低时,模型更重视历史信息,表明系统在冲击时会“记旧账”,风险的持续性更强。
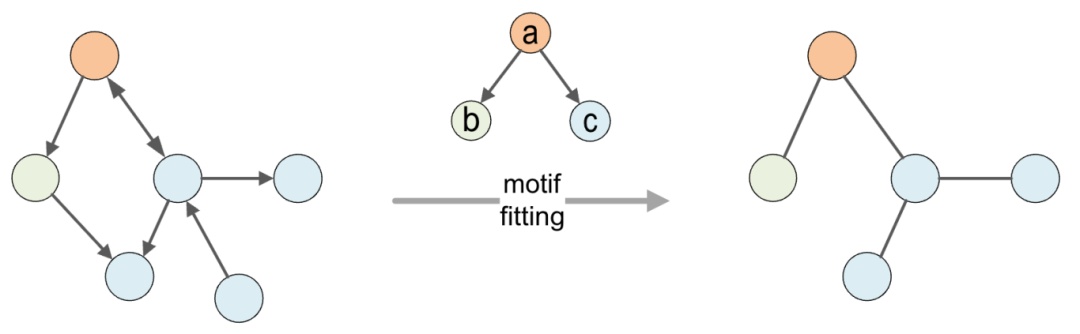
图2 Motif-8 网络结构示意图
三、数据与实证结果
研究选取了中国金融与房地产板块133家代表性机构,数据涵盖2020–2025年,重点分析了2022年房地产投资首次转负的背景下的风险动态。主要发现包括:
证券公司和高杠杆房企(Cluster 1)风险最高;中小房企和地方金融机构(Cluster 2)居中,大型商业银行和龙头房企(Cluster 3)相对稳健;
在日频数据下,FoPDE 模型的平均相对准确率(MRA)达到 95.5%,优于 LSTM 和 XGBoost,在周频数据下,MRA 也有 91.7%,同样表现稳定;
事件敏感性强
模型能捕捉到如恒大违约、相关政策刺激等关键事件对应的风险波动,风险事件前后模型参数α的下降体现出市场“拉长记忆”的机制。
图3 中国房地产投资增速趋势图
四、政策启示
文章提出了三点政策建议:
早期干预
分数阶参数能提前反映风险累积趋势,提醒监管在风险暴露前采取行动;
降低房地产金融化
过度依赖融资的房企和非银机构是风险高发点,应适度限制其杠杆;
增强核心银行韧性
大行虽处于低风险簇,但其“太大而不能倒”的地位意味着一旦出事,后果严重,需要持续压力测试与审慎监管。
研究展示了统计学与数学工具在现实金融问题中的跨界应用。通过引入分数阶PDE,作者提出的模型在预测精度上超越了主流机器学习方法,还能解释风险传播的内在机制。对于关心中国金融稳定与房地产市场走向的读者而言,这是一篇兼具理论创新与实践意义的成果。
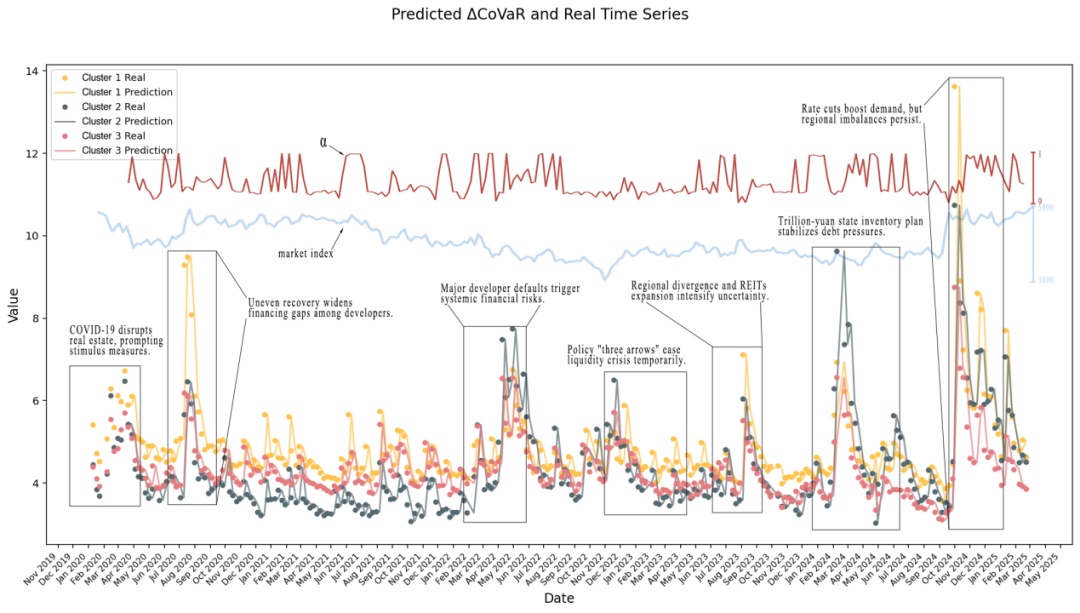
图4 预测结果对比图
责编:薛依宜