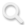转载自:智元机器人
3月10日,智元发布首个通用具身基座模型——智元启元大模型(Genie Operator-1),它提出了Vision-Language-Latent-Action (ViLLA) 架构,该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力,三者环环相扣,实现了可以利用人类视频学习,完成小样本快速泛化,降低了具身智能门槛,并成功部署到智元多款机器人本体,持续进化,将具身智能推上了一个新台阶。
2024年底,智元推出了 AgiBot World,包含超过100万条轨迹、涵盖217个任务、涉及五大场景的大规模高质量真机数据集。基于AgiBot World,智元今天正式发布智元通用具身基座大模型 Genie Operator-1(GO-1)。
01
GO-1:VLA进化到ViLLA
Latent Action Model(LAM,隐式动作模型)主要用于获取当前帧和历史帧之间Latent Actions的Groundtruth(真值),它由编码器和解码器组成。其中:
编码器采用Spatial-temporal Transformer,并使用Causal Temporal Masks(时序因果掩码)。
解码器采用Spatial Transformer,以初始帧和离散化的Latent Action Tokens作为输入。
Latent Action Tokens通过VQ-VAE的方式进行量化处理。
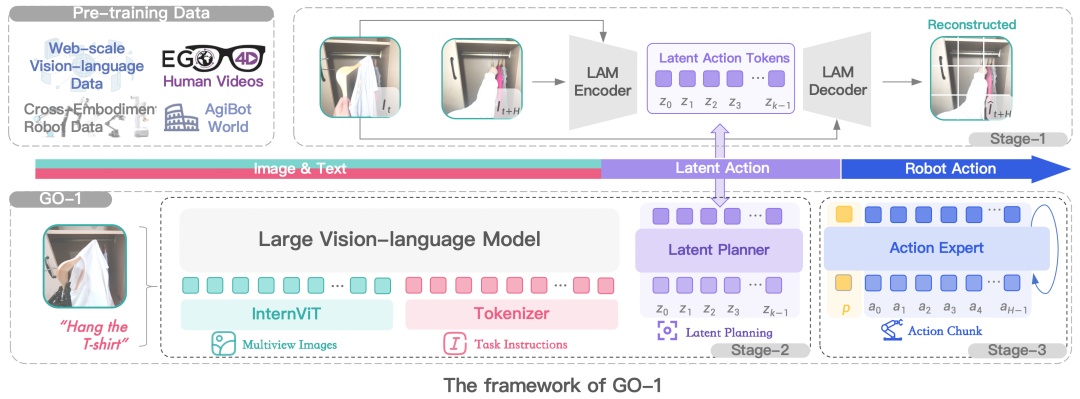
Latent Planner负责预测这些离散的Latent Action Tokens,它与VLM 主干网络共享相同的 Transformer 结构,但使用了两套独立的FFN(前馈神经网络)和Q/K/V/O(查询、键、值、输出)投影矩阵。Latent Planner这组专家会逐层结合 VLM 输出的中间信息,通过Cross Entropy Loss(交叉熵损失)进行监督训练。
Action Expert结构设计上与Latent Planner类似,也是与 VLM 主干网络共享相同的 Transformer 结构,但使用两套独立的FFN和Q/K/V/O投影矩阵,它通过Denoising Process(去噪过程)逐步回归动作序列。
Action Expert与VLM、Latent Planner分层结合,确保信息流的一致性与协同优化。
02
GO-1:具身智能的全面创新
人类视频学习:GO-1大模型可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解,更好地为人类服务。
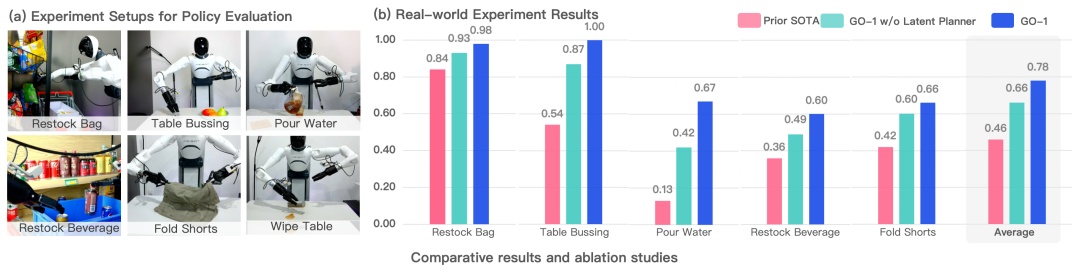
小样本快速泛化:GO-1大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低。
一脑多形:GO-1大模型是通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体,群体升智。
持续进化:GO-1大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。
从单一任务到多种任务:机器人能够在不同场景中执行多种任务,而不需要针对每个新任务重新训练。
从封闭环境到开放世界:机器人不再局限于实验室,而是可以适应多变的真实世界环境。
从预设程序到指令泛化:机器人能够理解自然语言指令,并根据语义进行组合推理,而不再局限于预设程序。
欢迎转发,但请注明出处“上海经信委”
觉得不错请点赞!